
I’m not a fan of obsessing over SOC metrics. If I get a call within 30 minutes after a confirmed True Positive I’m good.
But in the world of MSSPs (and sometimes even internal SOCs), metrics become the primary way to demonstrate effectiveness, especially to non-technical stakeholders. The more pressure there is to hit Service Level Agreement (SLA) targets, the more likely those numbers are to be gamed.
Before I start listing metrics and how those are skewed by MSSPs to meet SLAs there are two disclaimers I feel need to be made:
- SLA targets are sometimes unrealistic. Don’t blame analysts for not meeting impossible expectations.
- SLAs are only meaningful if tied to consequences. Your contract should clearly define what happens when SLAs are missed. This inclues specifying compliance threshold (e.g., 90%) and applying penalties.
With that said, let’s look at the most common SOC metrics and how MSSPs manipulate them to appear compliant.
SLA-aligned SOC metrics
In most cases, the metrics tracked and included in a SOC Service Level Agreement (SLA) focus on timeliness and responsiveness. The core SLA-aligned metrics typically include:
- Time to Acknowledge (TTA): The duration between alert generation and assignment to an analyst.
- Time to Close (TTC): The total time from alert creation to final closure.
- Escalation/Notification Time: The time, usually in minutes, to notify relevant stakeholders following the confirmation of a true positive alert.
- SLA Compliance Rate: The percentage of alerts or incidents handled within the agreed SLA thresholds.
A broader range of metrics may be included in monthly SOC performance reports (especially when the team is responsible for threat hunting, incident response, SIEM maintenance, detection engineering and more) but the metrics listed above are most commonly used as the foundation for SLA commitments.
How SOC SLA Metrics Are Often Skewed or Misrepresented
In my time working in SOC-adjacent roles, I’ve observed several tactics used by MSSPs to misrepresent SLA metrics. These practices can lead to misleading reports that overstate performance. Below are some common examples:
1. Including Automation in SLA
Metrics like Mean Time to Acknowledge (MTTA) and Mean Time to Close (MTTC) are only meaningful when they reflect human analyst activity. However, some MSSPs skew these metrics by including:
- Automatically assigned alerts
- Automatically closed alerts
Since these actions can occur within seconds, they artificially deflate MTTA and MTTC, giving the illusion of high responsiveness.
Best practice:
- Auto-handled alerts should be excluded from SLA-based metrics.
- Automation logic should be fully transparent to stakeholders.
2. SLA Reset During Escalation
A common but problematic tactic is resetting the SLA clock when an alert is escalated between tiers (e.g., from Tier 1 to Tier 2 or Tier 3). For example:
An SLA defines a 1-hour time to acknowledge and 1-hour time to close for high-severity alerts. The alert is picked up by Tier 1, then escalated to Tier 2, and finally Tier 3. If each team restarts the SLA timer, the total response time may stretch far beyond SLA limits, while still appearing compliant:
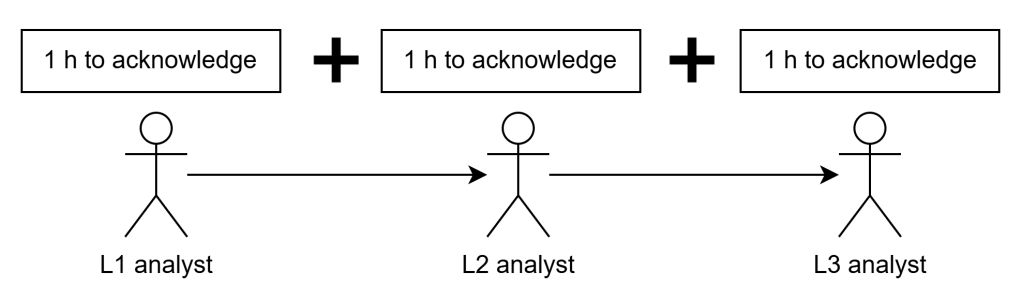
Best practice:
- Ensure SLA timer begins at initial alert generation and runs continuously across escalations.
3. Selective sampling
MSSPs often cherry-pick alerts that were handled within SLA and exclude alerts that were not. By far the most frequently excluded alerts are those that occured over the weekend. This one is difficult to see at a first glance and a second pair of eyes is often needed to prove certian alerts were omitted from the calculation.
Best practice:
- Require SLA reporting to include all alerts within the period, including weekends, holidays, and peak activity windows.
- Ask for raw data and calculate SLA yourself from time to time
4. Downgrading severity to extend SLA window
This one’s a classic. Suppose the SLA requires high-severity alerts to be closed within one hour, but an analyst is short on time or needs a break. A quick downgrade to medium severity buys another hour, no questions asked. This tactic is especially common when SLAs are unrealistically tight or the team is overwhelmed.
Best practice:
- Require justification for severity changes. Changes to alert severity must be an outcome of triage, not SLA pressure.
5. Fabricating Operational Issues to Excuse SLA Breaches
This one is, frankly, the most disappointing and unfortunately also the most common. It’s the tactic that erodes trust in a vendor faster than anything else.
When asked why an alert was missed or picked up late, some analysts will respond with vague or convenient excuses like:
- “We were facing technical issues.”
- “The cloud SIEM went down.” 🙂
- “The alert never showed up in the queue.”
These are often untrue and easily disproven with a quick check of audit logs, access records, or ingestion dashboards. It’s a defense mechanism, but one that signals deeper cultural or process issues within the SOC team.
Best practice:
- Any operational issue that impacts alert visibility or triage should be logged, acknowledged, and shared transparently. If the system is working, there’s no excuse not to act.
6. Vague or Misleading Definitions of Key Terms
One of the most subtle and effective ways to skew SLA reporting is through loose or inconsistent definitions of terms like “acknowledged,” “closed,” or “triaged.” When these aren’t clearly defined, it creates space for inflated performance numbers and misunderstandings between the MSSP and the client.
A common example is counting suppressed alerts or automatically resolved events toward the total number of “handled” alerts in monthly reports. Technically, no human touched them but they still get counted as if they were worked.
Best practice:
- Define clear, standardized meanings for all SLA-related actions: acknowledgment, triage, resolution, escalation, etc.
SLA metrics are meant to ensure accountability, transparency, and service quality, but without oversight can become little more than a box-ticking exercise. As we’ve seen, it’s not uncommon for MSSPs to manipulate metrics through tactics that are technically permissible but operationally misleading. Whether it’s suppressing alerts, resetting timers, or quietly downgrading severity, these practices undermine the very purpose of a SOC: protecting the business. The solution isn’t just tighter contracts or stricter SLAs – it’s shared clarity, auditability, and the courage to call out patterns that don’t feel right.





Leave a comment